
GraphQL DataLoader 사용하기
목표
GraphQL을 사용하다보면 쉽게 겪을 수 있는 문제인 N + 1 문제와, DataLoader라는 기술로 어떻게 해결할 수 있는지 알아보자.
N + 1 문제
N + 1 문제란 무엇일까? 예시로 알아보자. 상품(Product)에는 리뷰(Review)들이 존재한다. 그래서 개발자는 product쿼리 안에 reviews를 추가하고 리졸버에 reviews를 가져오는 로직을 추가할 수 있다.
query GetProductDetail($productId: ID!) {
product(id: $productId) {
id
title
price
reviews {
id
content
}
}
}
위의 쿼리를 실행하면 DB에서는 2번의 SELECT가 수행된다.
- Product(id: 1)를 SELECT 한다.
WHERE productId = ?로 Review를 SELECT한다.(productId: 1)
상품을 여러개 불러오는 products라는 쿼리도 존재한다. 개발자는 상품을 여러개 가져오는 쿼리에 reviews를 추가할 수 있다.
query GetProducts {
products {
id
title
reviews {
id
content
}
}
}
위의 쿼리를 실행하면 DB에서는 몇 번의 SELECT가 일어날 수 있을까?
- Product 10개를 SELECT 한다.
SELECT * FROM Review WHERE producId = 1;SELECT * FROM Review WHERE producId = 2;SELECT * FROM Review WHERE producId = 3;
…
N + 1. product: 10에 대한 리뷰 ~개를 가져온다.
총 10 + 1 의 SELECT 문이 실행된다. 만약 size가 10이 아니라 더 많이 가져오거나 동시에 조회하는 유저가 많아진다면 DB에 엄청난 부하가 들게 되고, 이 문제를 N+1 문제라고 한다. N + 1문제는 GraphQL을 사용할때만 발생하는 문제는 아니고 다양한 상황에서 겪을 수 있다.
N + 1 문제 해결하기
N + 1 문제를 해결하는 방법은 여러가지가 있는데 이 게시글에서는 DataLoader에 대해 소개하고자 한다. DataLoader 공식 github 문서에는 DataLoader를 이렇게 소개하고 있다.
DataLoader is a generic utility to be used as part of your application’s data fetching layer to provide a simplified and consistent API over various remote data sources such as databases or web services via batching and caching.
요약하자면 배치 및 캐싱 기능을 통해 단순하고 일관된 API를 제공하는 애플리케이션의 fetching layer에서 사용될 수 있는 유틸이라고 한다. 여기서 주목할 점은 데이터로더가 배치 및 캐싱 기능을 사용한다는 점이다.
데이터 로더의 배치 기능
데이터로더는 여러개의 개별 요청을 하나로 합친다. (이벤트 루프의 tick단위) 그 후에 요청에 해당 되는 값을 리턴하는 배치 로딩 함수를 필수로 구현해줘야 한다. 배치 로딩 함수는 key의 배열을 인자로 받고 그 결과값을 Promise로 반환해야만한다. (async 함수여야함)
async function reviewBatchLoader(keys) {
const reviews = await reviewService.findByProductIdsIn(keys);
return keys.map((key) =>
reviews.filter((review) => review.productId === key)
);
}
여기서 꼭 지켜줘야하는 규칙이 2가지 있다.
- key배열의 길이와, 값의 배열의 길이는 반드시 같아야한다.
- key배열의 인덱스와, 값의 배열의 인덱스는 반드시 같아야한다.
keys배열의 길이와 순서는 반드시 일치해야한다는 것이다. 만약 요청으로 받은 key값에 해당하는 값이 없다면 null이나 에러라도 리턴해줘야한다. 의 규칙을 지켜서 배치 로딩 함수를 만들 수 있다.
공식 문서의 예제위의 예시로 Product의 id가 key로 들어온다면 ReviewLoader에서는 WHERE productId IN (?) 조건문으로 단 한 번만 쿼리를 실행해주면 된다.
데이터 로더의 캐싱 기능
데이터 로더는 캐싱 기능도 제공한다. DataLoader 인스턴스 내에는 캐시맵이 존재한다. 한 번의 요청에 reviewLoader.load를 2번 부른다면 1번째 요청에서는 내부 로직을 수행한 후, 결과값을 캐시맵에 저장하고, 2번째 요청부터는 캐시맵에 저장되어있던(메모이제이션되었던) 결과 값을 리턴한다.
// dataloader/src/index.js에서 cacheMap에 결과값을 set 하는 코드를 확인할 수 있다.
load(key: K): Promise<V> {
...
// If caching, cache this promise.
if (cacheMap) {
cacheMap.set(cacheKey, promise);
}
return promise;
}
데이터로더의 캐시는 redis나 memcache 같은 어플리케이션을 대체하는 용도가 아니므로, 단일 요청에서 동일한 데이터를 중복 로드하지 않는 용도로만 사용해야한다.
따라서, DataLoader를 사용할땐 한 번의 요청에 하나의 인스턴스를 사용하도록 해야한다. (요청이 올때마다 매번 새로운 인스턴스를 만든다.) 만약 캐싱기능을 사용하지 않을것이라면 { cache: false } 설정으로 캐싱을 OFF할 수 있다.
reviewLoader: new DataLoader(reviewBatchLoaderFn, { cache: false })
GraphQL 어플리케이션에 적용하기
실제로 GraphQL 어플리케이션에 적용하려면 어떻게 해야할까? 주로 dataloader는 resolver에서 공용으로 사용하는 context 에 넣어서 사용한다.
async function reviewBatchLoaderFn(keys) {
const reviews = await reviewService.findByProductIdsIn(keys);
return keys.map((key) =>
reviews.filter((review) => review.productId === key)
);
}
const server = new ApolloServer({
typeDefs: typeDefs,
resolvers: resolvers,
context: () => ({
loaders: {
reviewLoader: new DataLoader(reviewBatchLoaderFn)
},
}),
});
context의 initalize function은 요청마다 실행되므로 위에서 언급했던 요청이 들어올때마다 데이터로더 인스턴스를 생성할 수 있다.
리졸버에서 데이터로더의 load 함수를 사용하면 된다.
const resolvers = {
Query: {
...
},
Product: {
reviews: async (parent, _, context) => {
return await context.loaders.reviewLoader.load(parent.id);
},
},
};
batch가 잘됐는지, caching이 동작하는지 확인하기 위해, 로그를 추가하고 load를 2번 해보았다.
async function reviewBatchLoaderFn(keys) {
console.log("keys = ", keys);
const reviews = await reviewService.findByProductIdsIn(keys);
return keys.map((key) =>
reviews.filter((review) => review.productId === key)
);
}
...
Product: {
reviews: async (parent, _, context) => {
// 테스트를 위해 2번 로드
await context.loaders.reviewLoader.load(parent.id);
return await context.loaders.reviewLoader.load(parent.id);
};
}
// 출력값
keys = [
'1', '2', '3',
'4', '5', '6',
'7', '8', '9',
'10'
]
2번 로드해도 keys값은 1번만 프린트되는걸 확인할 수 있었다.
실수하기 쉬운 부분
- 요청마다 새로운 DataLoader 인스턴스를 만들어야 한다.
- 보통 상태가 없는 클래스는 인스턴스를 재사용한다. 그래서 아무생각없이DataLoader도 인스턴스를 재사용할 수 있는데, 인스턴스가 상태를 가지고 있으므로(캐싱된 값을 저장하므로) 원하지 않는 결과값을 얻을 수 있다.
따라서 인스턴스를 재사용하고 싶으면
cache: false옵션을 주고, context 가 아닌 다른 곳에서 인스턴스를 만들어서 사용해야한다.
- 보통 상태가 없는 클래스는 인스턴스를 재사용한다. 그래서 아무생각없이DataLoader도 인스턴스를 재사용할 수 있는데, 인스턴스가 상태를 가지고 있으므로(캐싱된 값을 저장하므로) 원하지 않는 결과값을 얻을 수 있다.
따라서 인스턴스를 재사용하고 싶으면
- keys 인덱스의 순서와, 결과값의 순서가 일치해야한다.
- param으로 들어오는 keys의 순서와, 결과값의 순서가 반드시 일치해야 한다. 만약 순서가 다르다면, 엉뚱한 결과값이 나오게 될것이다. 순서를 맞추기 위해, keys 기준으로
map,for문을 돌리는것이 좋다. 또한, length 도keys.length와 동일해야한다. 길이가 다르면 아래와 같은 에러가 발생한다.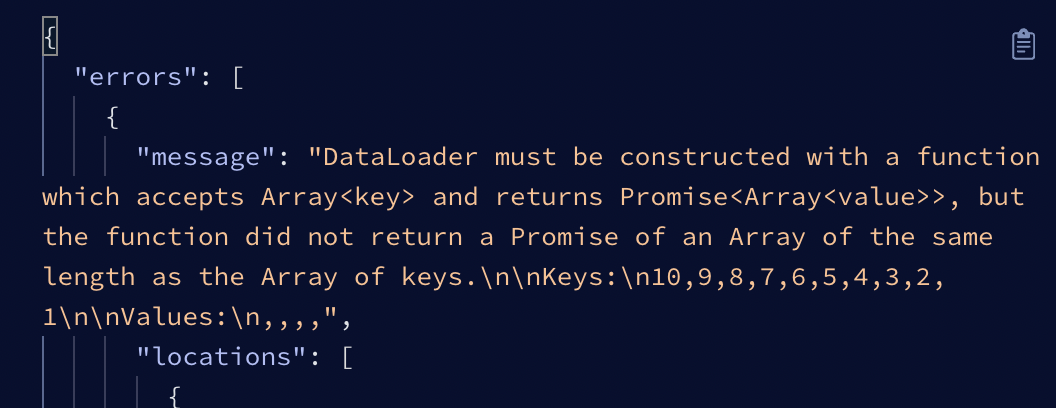
- param으로 들어오는 keys의 순서와, 결과값의 순서가 반드시 일치해야 한다. 만약 순서가 다르다면, 엉뚱한 결과값이 나오게 될것이다. 순서를 맞추기 위해, keys 기준으로
참고
- dataloader 공식문서: https://github.com/graphql/dataloader
- 블로그 글[GraphQL DataLoader를 이용한 성능 최적화]: https://y0c.github.io/2019/11/24/graphql-query-optimize-with-dataloader/